A survey on deep learning and its applications
Un article présenté par Valentin Poli, Tristan Denis et François Bolot.
Le deep learning est un domaine de l’intelligence artificielle qui utilise des réseaux de neurones artificiels profonds pour résoudre des problèmes complexes tels que la reconnaissance de la parole et de l’image. Les bases de ce domaine remontent aux travaux de McCulloch et Pitts dans les années 1940, mais les avancées majeures sont survenues dans les années 1980 et 1990 avec de nouvelles architectures et techniques d’apprentissage, notamment les réseaux LSTM et l’apprentissage basé sur les gradients. Le terme “deep learning” a été mentionné pour la première fois en 2006 et depuis lors, ce domaine a connu une croissance rapide grâce à la disponibilité de grandes quantités de données et à la puissance de calcul accrue. Les réseaux de neurones profonds sont composés de nœuds neuronaux interconnectés qui traitent les informations de manière similaire au cerveau humain. Les fonctions d’activation introduisent de la non-linéarité dans les calculs des réseaux, tandis que l’entraînement peut être supervisé ou non supervisé, en fonction des données disponibles. Le deep learning nécessite une grande quantité de données et une puissance de calcul élevée pour obtenir des performances optimales.
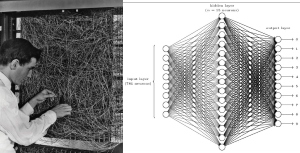
Modèles de Deep Learning
Les encodeurs automatiques sont des modèles d’apprentissage non supervisés utilisés pour découvrir une représentation latente comprimée et plus informative des données en entrée. Ils se composent d’un encodeur, d’un décodeur et d’une couche cachée. L’encodeur permet au système de reconnaître les motifs dans une classification en minimisant l’erreur entre le signal d’entrée et le signal reconstruit. La représentation latente peut être utilisée comme entrée pour un modèle de prédiction ou pour reconstruire l’entrée du système afin de débruiter une image. De plus, l’erreur de reconstruction peut également être utilisée pour détecter les anomalies dans les données.
Le stacking automatique d’autoencodeurs est une technique avancée de machine learning qui combine plusieurs modèles d’autoencodeurs différents pour obtenir une prédiction finale plus précise. Les stacked autoencoders sont utilisés pour apprendre des représentations de données de plus en plus complexes et hiérarchiques en empilant plusieurs structures d’auto-encodage simples. Cette technique est couramment utilisée pour la préparation des données, la réduction de dimensionnalité et l’amélioration de la précision de prédiction.
La Boltzmann machine est un modèle probabiliste génératif utilisé pour modéliser les distributions de probabilité des données d’entrée. Elle utilise un graphe bipartite et un échantillonnage de Gibbs pour trouver des patterns et extraire les features les plus importantes des données. La Boltzmann machine peut être utilisée pour résoudre divers problèmes, tels que la régression, la classification, la réduction de dimensionnalité et la modélisation de séries temporelles.
Le réseau de croyance profonde est une architecture de réseau de neurones qui utilise plusieurs couches de Restricted Boltzmann Machines (RBM) pour extraire des caractéristiques des données d’entrée. Il résout le problème de vanishing gradient en utilisant l’apprentissage couche par couche grâce à la méthode de Contrastive Divergence (CD). Le réseau de croyance profonde a été utilisé avec succès dans des tâches telles que la reconnaissance vocale et le traitement d’images.
La Machine de Boltzmann Profonde (DBM) est formée par une pile de machines de Boltzmann restreintes. Elle peut apprendre des représentations intrinsèques plus complexes et construire une représentation plus élevée dans un grand nombre de données non étiquetées. La DBM utilise l’apprentissage non supervisé, l’algorithme de moyenne de champ et le réglage fin supervisé pour améliorer la précision et la diffusion des informations.
Le réseau de convolution est utilisé pour traiter les images en réduisant le nombre de paramètres nécessaires pour entraîner le réseau. Il utilise des matrices de convolution partagées entre différents neurones pour analyser les champs récepteurs de l’image, ce qui permet de mieux traiter les données de grande taille.
Enfin, le deep learning on graph et le graph de réseau de neurones abordent les défis spécifiques liés à l’apprentissage sur des ensembles de données de graphes en raison de leurs structures et de leur dimensionnalité irrégulières. Ces approches utilisent des réseaux de neurones pour apprendre à représenter et à classer les nœuds et les graphes
Exemples d’applications de Deep Learning
Lorsqu’il s’agit de traduction automatique, deux des acteurs majeurs sont DeepL et Google Traduction. DeepL est réputé pour ses performances de traduction de haute qualité grâce à l’utilisation de réseaux de neurones profonds (DNN). Il utilise des modèles de traduction neuronale qui ont été entraînés sur de grandes quantités de données multilingues. Google Traduction, quant à lui, utilise également des réseaux de neurones profonds, mais ses performances peuvent varier en fonction des langues et des contextes.
Passons maintenant à la reconnaissance faciale. En 2015, un modèle révolutionnaire appelé FaceNet a été introduit. Il utilise un type de réseau de neurones appelé réseau de neurones convolutifs (CNN) pour extraire les caractéristiques distinctives des visages. Cette technologie a permis de réaliser des avancées significatives dans la reconnaissance faciale.

En ce qui concerne le suivi des objets dans l’espace (ISS), l’utilisation de modèles basés sur des champs aléatoires conditionnels (CRF) en combinaison avec des convolutions et des unités de traitement graphique (GPU) permet d’obtenir une précision et une vitesse accrues. Les CRF sont utilisés pour modéliser les relations entre les différentes parties de l’objet suivi, tandis que les convolutions et les GPU permettent un traitement parallèle rapide.
Un autre domaine d’intérêt est l’entraînement et l’optimisation des modèles. Il est essentiel de mettre à jour et d’améliorer les méthodes d’entraînement, en explorant des approches supervisées et non supervisées, voire une combinaison des deux. Trouver des moyens d’effectuer un apprentissage non supervisé pur constitue également un défi majeur.
L’optimisation des paramètres joue également un rôle crucial dans l’efficacité des modèles:
-
Le taux d’apprentissage (learning rate) doit être réglé avec soin, car une valeur trop petite peut entraîner une convergence lente, tandis qu’une valeur trop grande peut entraîner la non-convergence vers le point optimal.
-
Les optima locaux et les points selle sont des obstacles supplémentaires, et bien que des méthodes existent pour les détecter à l’aide de matrices hessiennes, leur utilisation peut être trop coûteuse en termes de temps de calcul pour les réseaux de neurones qui nécessitent des performances rapides.
Enfin, la réduction du temps d’apprentissage est un défi à relever. L’utilisation de plus de données et de réseaux plus grands nécessite un temps d’apprentissage plus long, ce qui peut être problématique dans certaines applications où une réponse rapide est essentielle.
